整然データとは何か
はじめに
データ分析の際には、データが扱いやすい形式になっている必要がある。データの中身がぐちゃぐちゃになっていたり、データの形式が統一されていなかったりすれば、分析は骨の折れる作業となる。
それでは、どのようなものがデータ分析において扱いやすい形式のデータになるのだろうか。この問題に対する唯一の正しい解答というものは存在しない。しかし、表の形式で表すことができるデータを考える場合、ハドリー・ウィッカム (Hadley Wickham) 氏が提唱した整然データ (tidy data) ((“tidy data”を「整然データ」と日本語訳した理由については「なぜ“tidy data”を「整然データ」と訳したのか」という記事を参照のこと。)) が1つの解答となりうる。整然データは、構造と意味が合致するという極めて有用な特徴を持っている。
データ分析でよく使われるR言語では、整然データを扱うためのツールが充実している。例えば、Rにおけるグラフ作成のパッケージとして広く使われているggplot2は、整然データを入力として受け取ることで容易にグラフが描けるようになっている。このため、Rを使ってデータ分析を行う人は、ぜひこの整然データという概念について把握しておくとよい。また、R以外の統計処理ソフトやプログラミング言語を使ってデータ分析を行う人であっても、この概念を知っておいて損はないだろう。
整然データの4つの条件
それでは、具体的にどのようなものを整然データと呼ぶのだろうか。ここでは、ハドリー・ウィッカム氏が2014年に出した論文 ((Wickham, H. (2014). Tidy data. Journal of Statistical Software, 59 (10). doi:10.18637/jss.v059.i10))での議論に従って、整然データについて説明していきたい。なお、この論文については、本サイトで「整然データ」という和訳を公開しているので、興味がある方はそちらもご覧いただきたい。
さて、ウィッカム氏は、2014年の論文で、整然データの条件として以下の3つのことを挙げている。なお、列とは縦方向に並んだもの、行は横方向に並んだものを指す。どちらがどちらか覚えられない場合は、「行列で縦か横か迷ったら」という記事を参照のこと。
- 個々の変数 (variable) が1つの列 (column) をなす。
- 個々の観測 (observation) が1つの行 (row) をなす。
- 個々の観測の構成単位の類型 (type of observational unit) が1つの表 (table) をなす。
このほかに、「個々の値 (value) が1つのセル (cell) をなす」という4つ目の条件がある。この4つ目の条件は、2014年の論文では明確に示されていないものの、ウィッカム氏が2017年に出したデータ分析の教科書 R for Data Science ((Wickham, H. & Grolemund, G. (2017). R for Data Science. Sebastopol, CA: O'reilly.)) で整然データを扱った第12章に出てきている。
また、整然でないデータのことを雑然データ (messy data) と呼ぶ。
この4つの条件を見るだけでは、何が整然データか想像することは難しいだろう。というわけで、実例を1つ見てみたいと思う。
整然データの実例
ある日の天気を調べたデータを考える。このデータにおいては、札幌・東京・福岡の3地点において、6時間おきに天気を記録している。このデータを2種類の形式で表したものを以下に掲げる。いずれも表している内容は全く同じであるが、形式だけが異なっている。つまり、意味は同じであるが、構造が違うのである。
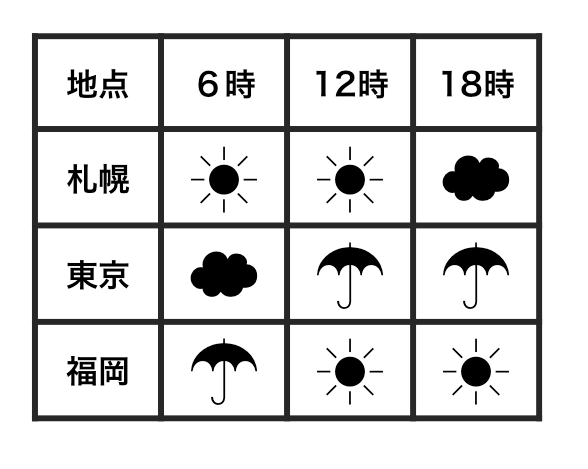
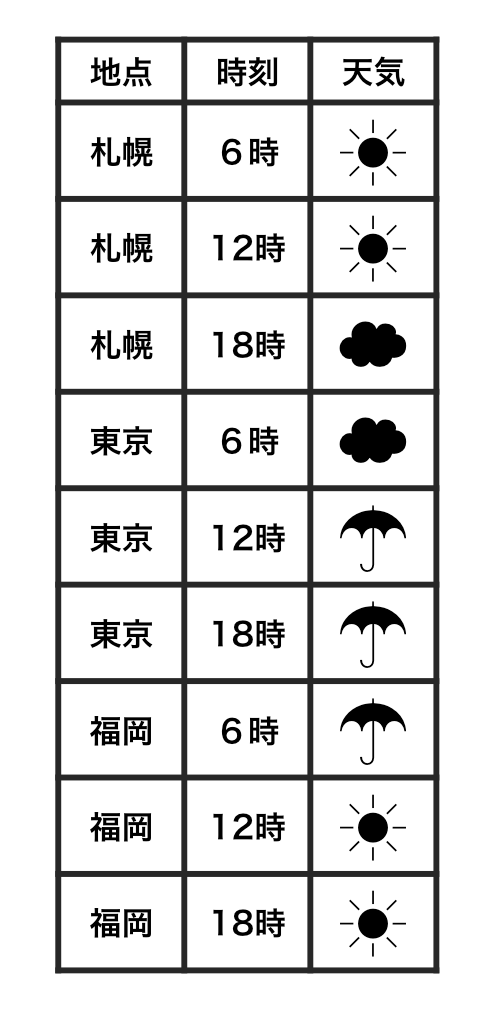
ここで、1つ目に掲げたものは整然でない(すなわち雑然である)。これに対して2つ目に掲げたものは整然である。なぜ片方が整然でなく、片方が整然であると言えるのだろうか。
変数と列
まずは両者において変数がどのように表示されているかを見てみたい。このデータにおいては、地点・時刻・天気という3つの変数がある。
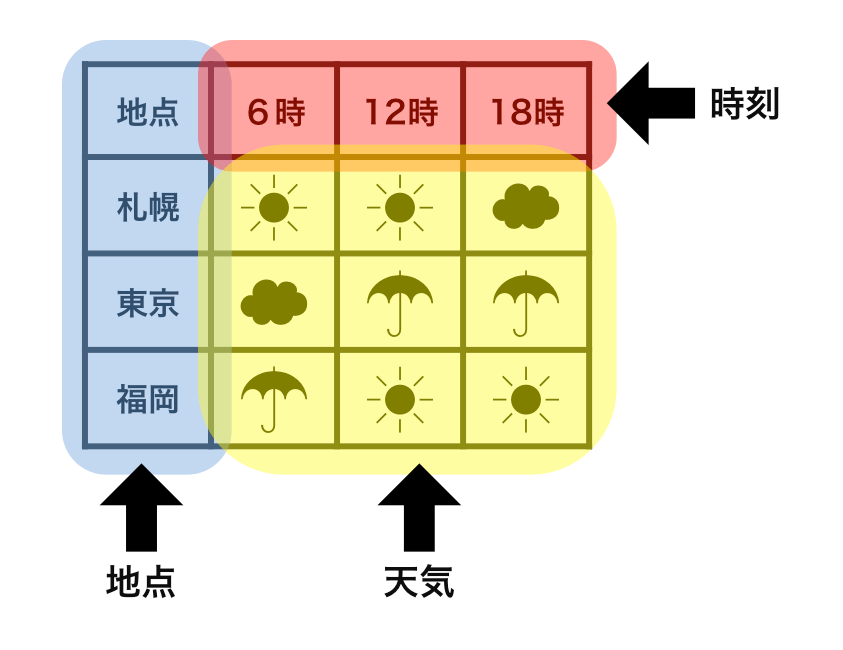
1つ目の表においては、地点の情報は列で表されているが、時刻の情報は行で表されている。天気の情報は複数の行と列にまたがっている。地点も時刻も天気も意味的には変数であるにも関わらず、表出された構造が異なっている。そして、整然データの1つ目の条件(個々の変数が1つの列をなす)は満たされていない。
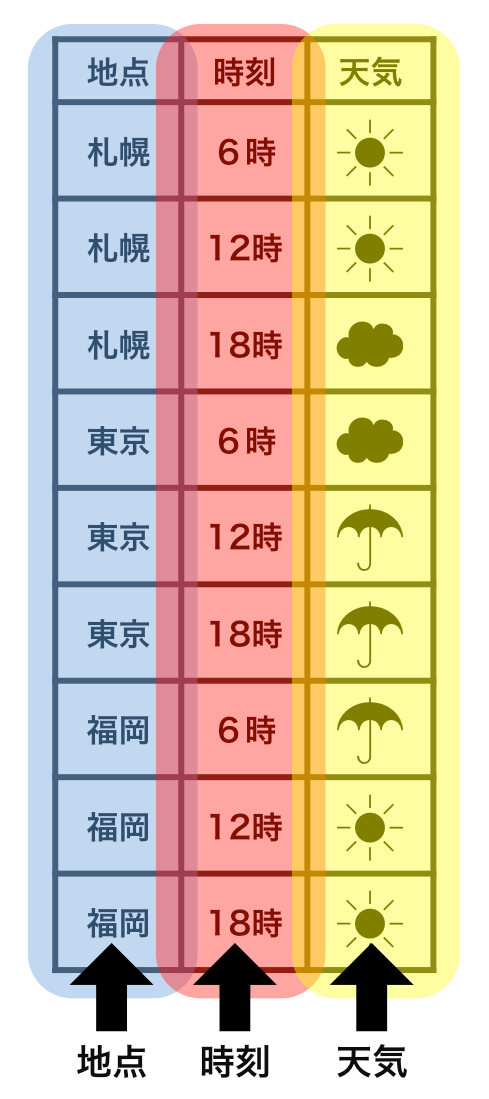
これに対して、2つ目の表ではどの変数も1つの列で表されている。地点の情報は縦一本になっているし、時刻の情報も縦一本になっている。天気も同様だ。つまり、こちらは1つの変数が必ず1つの列をなしており、整然データの1つ目の条件を満たしている。
観測と行
今度は1つの観測がどのように表されているかについて見てみよう。今見ているデータでは、9つの観測が行われている ((1) 札幌で6時に行われた観測、2) 札幌で12時に行われた観測、3) 札幌で18時に行われた観測、4) 東京で6時に行われた観測、5) 東京で12時に行われた観測、6) 東京で18時に行われた観測、7) 福岡で6時に行われた観測、8) 福岡で12時に行われた観測、9) 福岡で18時に行われた観測。)) 。
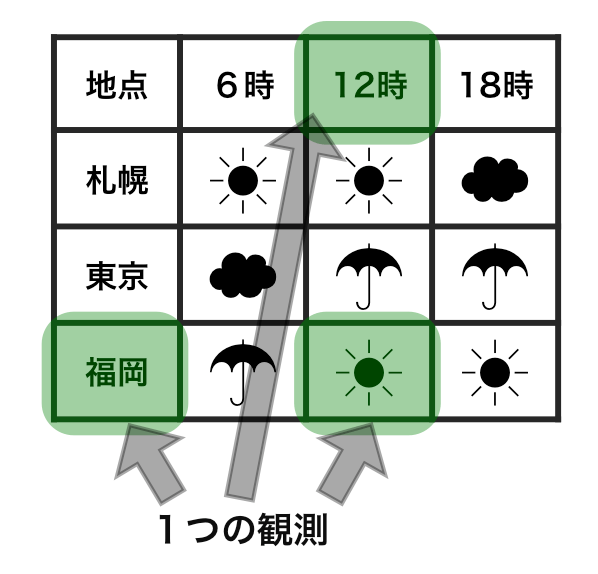
1つ目の表においては、1つの観測が単純な形をしていない。例えば、図に示したように、福岡で12時に晴れだったという観測に関する情報はばらばらになってしまっている。この観測を抽出するコードを書くことはさほど容易なことではない。
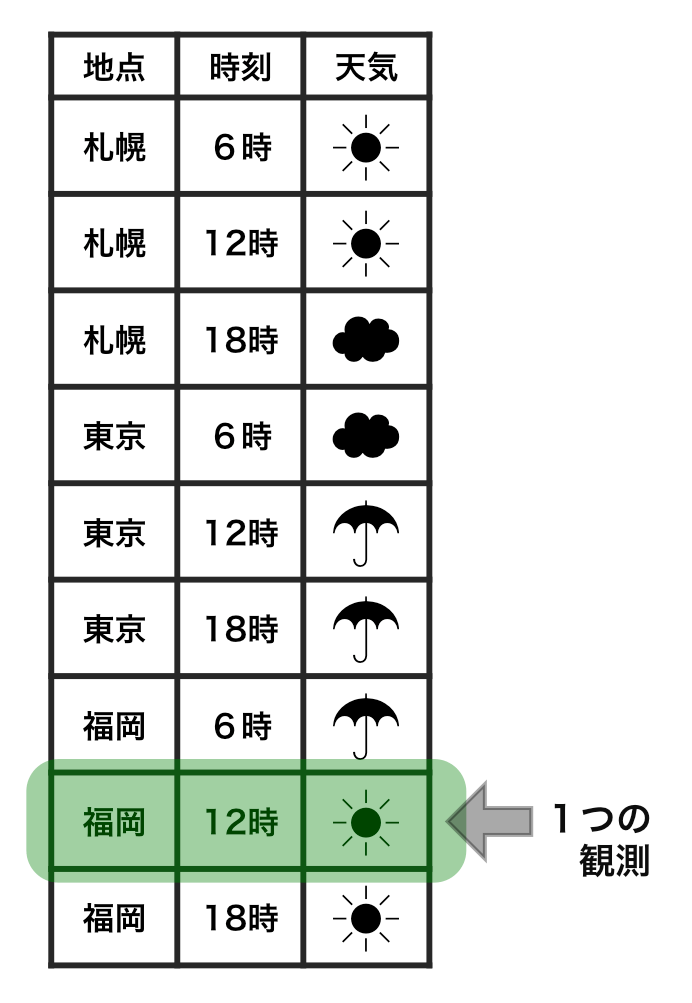
これに対して、2つ目の表においては、1つの観測が1つの行という単純な形で示されている。つまり、こちらは、整然データの2つ目の条件(個々の観測が1つの行をなす)を満たしているのである。
類型と表
整然データの3つ目の条件(個々の観測の構成単位の類型が1つの表をなす)について、まだ触れていなかったので、ここで補足しておきたい。この条件は、端的に言えば2つのことを含意する。
1つ目は、1つの表には種類の違う観測が入っていてはならないということである。先ほどの天気の例で言えば、表の中に天気を観測したもののほかに、ラーメン店の日々の売り上げを観測したもの ((日常的な感覚では、観測と言うと、気象観測や天体観測のように科学的なもののみを指すことになるだろう。しかし、ここでは科学的なもの以外でも観測として考えている。)) が入っていてはいけない。もし入っていれば、整然ではなくなる ((2017年1月11日:この文の誤字修正。)) 。このように類型の異なるものが1つの表に入っていれば、データ分析がしづらいことはすぐに分かるだろう。
2つ目は、同じ種類の観測が複数の表にまたがっていてはならないということである。先ほどの天気の例で言えば、6時の観測と12時の観測が別々の表に記録されていれば、それは整然とはならない。すぐに想像が付くだろうが、同じ種類の観測は、普通ひとまとめにして分析することになるので、1つの表にまとまっていた方が分析しやすいのである。複数の表にまたがっていては、簡単に分析することはできない。
値とセル
最後に、整然データの4つ目の条件(個々の値が1つのセルをなす)ということについても簡単に触れておきたい。
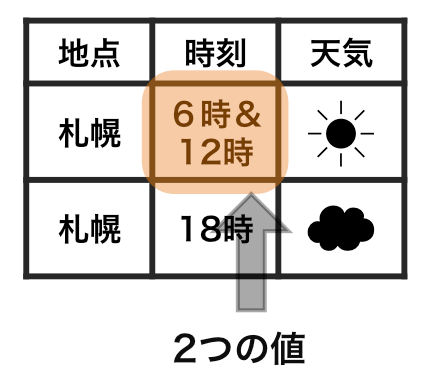
もし、1つのセルに2つ以上の値が入っていれば、整然にはならない。例えば、札幌で6時も12時も晴れだったからといって、それをまとめて「6時&12時」という形で2つの値を1つのセルに記しては、整然でなくなる。
また、1つの値の情報が2つ以上のセルに分かれてしまっているという場合も、整然にはならない。こうした状況は想像しにくいかもしれないが、何らかの2桁のコードがあったときに、1桁目と2桁目が別々のセルに格納されてしまっている状況はこれに当てはまるだろう。
構造と意味の合致の重要性
整然データには、1つの構造上の単位と1つの意味上の単位とが対応しているという特徴がある。例えば、整然データにおいては、1つの列という構造上の単位が、1つの変数というデータの意味上の単位に必ず対応する。
構造と意味とが合致していると、分析は非常に容易になる。
そもそも、我々がデータ分析を行う目的は、多くの場合、データにおける意味上の関係を見いだすことに帰結する。構造上の関係を見たいのではなく、意味上の関係を見たいのである。我々は、例えば、7列目が12列目にどう影響するかといった構造上の関係を知りたいのではなく、学歴が年収にどう影響するかといった意味上の関係を知りたいのである。
しかし、分析プログラムを書く場合は、19列目と38列目の差を求めさせるといった形で、構造上の単位をもって記述することが多くなる。つまり、本当は意味上の関係を知りたいのだが、計算機に対しては構造上の関係を分析させることになるのである。
ここで、構造と意味とが合致していなければ、人間が考えていることを計算機に理解させるための余計な翻訳をはさむ必要が出てくる。しかし、整然データのように、構造と意味が合致していれば、人間が考えた意味をほとんどそのまま計算機にわたす構造とすることができるのだ。
整然でないデータの意義
今まで、整然データの意義について述べてきた。このことは、整然でないデータ、すなわち雑然データにまったく意義がないことを示唆するものではない。整然でないデータも、状況によっては役に立つ。
先に挙げた天気の例では、人間が見るのであれば、整然でないものの方が分かりやすいだろう。例えば、同じ時刻の異なる地点の天気を比較したければ、先に挙げた整然でないものの方が比較しやすいはずだ。また、紙に印刷するのであれば、先に挙げた整然でないものの方が紙幅を節約できる。
Rと整然データ
さて、R言語には、整然データに取り組むための道具立てが多数用意されている。こうした道具立てを組み合わせることにより、データ分析を効率的に行うことができる。以下では、Rにおいて整然データに取り組むためのパッケージを紹介する。
なお、ここで紹介するパッケージは、すべてハドリー・ウィッカム氏が開発に携わったものである。そして、これらのパッケージは、ウィッカム氏が用意したtidyverseというパッケージに含まれている。tidyverseをinstall.packages("tidyverse")でインストールし、library("tidyverse")で読み込めば、以下で紹介するパッケージを逐一準備しなくても使うことができる。
整然データを作りあげる
現実に存在するデータは必ずしも最初から整然データになっているわけではない。このため、データを加工して、整然データを作りあげる必要がある。
整然データを作る際に良く用いられるのが、tidyrというパッケージである。このパッケージに出てくる函数を使えば、例えば、先ほどの天気のデータの例で整然でなかったデータをすぐに整然データに変換することができる。
整然ツール
入力されるデータも出力されるデータも整然データであるツールのことを整然ツール (tidy tool) と呼ぶ。R言語においては、さまざまな整然ツールが用意されている。例えば、dplyrパッケージには、観測をしぼりこむために用いるfilter()、値を集約するために用いるsummarise()といったツールがあり、これらは整然データを受け付けて、整然データを返す。また、グラフ作成用のパッケージであるggplot2も整然データを入力として受け付ける ((ggplot2パッケージは、データでなくグラフを出力するので、出力されるデータが整然かどうかは考えなくて良い。)) 。
整然ツールを組み合わせれば、分析は非常に容易になる。なぜなら、ある整然ツールの出力が、別の整然ツールの入力としてそのまま使えるからである。もし、あるツールの出力の形式と、別のツールの入力の形式が合っていなければ、途中で形式を変換する必要が出てくるだろう。しかし、整然ツールは出力も入力も整然データという同じ形式であるため、途中の変換は不要になる。
もっと知りたい人のために
整然データという概念については、以下の論文において詳しい説明がなされている。
- Wickham, H. (2014). Tidy data. Journal of Statistical Software, 59 (10). doi:10.18637/jss.v059.i10
この論文を和訳したものとして「整然データ」という記事を本サイトで公開しているので、日本語で読みたい方はこちらをご覧いただきたい。
また、整然データを扱うという視点も入ったデータ分析の教科書として以下のものがある。
- Wickham, H. & Grolemund, G. (2017). R for Data Science. Sebastopol, CA: O'reilly.
この本の第12章はまさに整然データを扱った章になっている。また、ほかの章では、先に挙げたRのパッケージの使用方法などが書かれている。なお、この本の内容は、著者のウェブサイトで無料で閲覧することができる。