はじめに
最近の言語学の論文では、Google などのサーチエンジンでのヒット数を議論の証拠としていることが結構ある。例えば、ある表現を Google で検索したところ5万件ヒットし、同様に別の表現を検索したところ500件しかヒットしなかったので、前者の方がよく使われる表現である、と主張するのである。
結論を先に言うと、Google などのサーチエンジンでのヒット数を言語研究の証拠とすることには問題が多い。問題点の1つとして、ヒット数に再現可能性がないことが挙げられる。ヒット数は安定的な数値ではなく、急変しうる。言語研究も科学的研究である以上、このような再現可能でないものを証拠として使うのは問題がある。また、サーチエンジンが検索対象としている範囲は本当に言語を「代表」するものなのかという問題もある。こういった問題を以下で詳しく見ていこう。
ヒット数を証拠にするとは?
Google などのサーチエンジンでのヒット数を言語研究の証拠に用いるとはどういうことだろうか?
仮想的な事例として、日本語のら抜き言葉 [1] を研究する場合を考えてみよう。ら抜き言葉と言っても、ら抜きになりやすい動詞とそうでない動詞がある。一般には「見る」や「食べる」はら抜きを起こしやすく、「信じる」や「考える」はら抜きを起こしにくいと言われている。
このことを確かめるために、Google でのヒット数を見てみよう。検索してみたところ、「見られる」が1億4100万件、「見れる」が6680万件であった。つまり、「見る」に対してはら抜きでない形とら抜きの形が、2.11対1の比率で出現していることになる。これに対して、「信じられる」が574万件、「信じれる」が91万8千件であった。つまり、6.25対1だ。「見る」と「信じる」での比率の差から、明らかに「見る」の方が、ら抜きを起こしやすいと結論づけるわけだ。
サーチエンジンのヒット数を調べるのは、割と簡単なので、こういった手法が結構使われているのである。前に、「Googleのヒット数を用いて意味の関わりの強さを測る手法」という記事をこのブログで書いたが、これもヒット数を用いる指標である。
だが、サーチエンジンのヒット数は、以下で触れるように、様々な問題点がある。
ヒット数は大きく変動する
サーチエンジンでのヒット数は、大きく変動することがある。ウェブ上の文書は、刻々と切り替わるわけだから、それに応じてヒット数も変化するのである。さらに、サーチエンジンの仕様によるためなのか、極めて短時間の間に、不自然なほどヒット数が増減することもある。
例えば、佐藤ら (2011) [2] は、2009年10月から2010年12月の14ヶ月にわたり、Yahoo! で「東宝シネマ」という言葉を検索したときのヒット数を調査している。
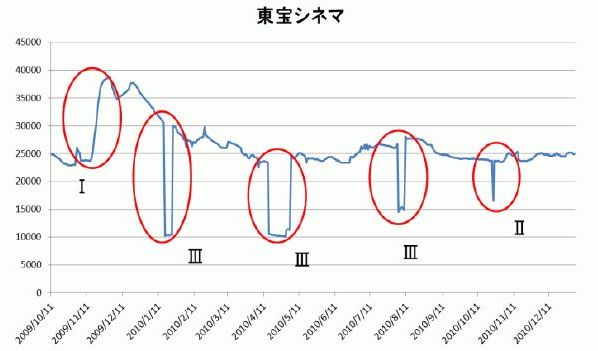
上の図 [3] に示されているように、ヒット数が安定している時期もあるが、ヒット数が大幅に変動している時期もある。もし、たまたま急降下しているときのヒット数を証拠として使ってしまったとしたら、大きな問題が生じるであろう。
もう1つ例を見てみよう。以下の図は、田野村 (2008) [4] が、Googleにおける「東京に行く」と「東京へ行く」のヒット数の結果を示したものである。
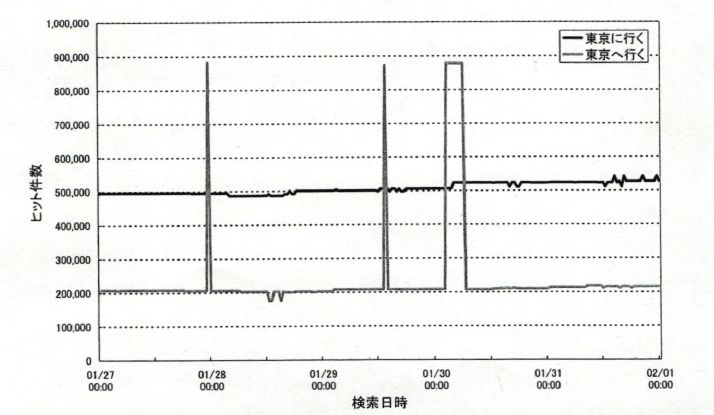
先に挙げた「東宝シネマ」の例は14ヶ月という長期にわたるものであった。これに対して、上の図の例はたった5日間の間のものである。極めて短い時間の間でも、ヒット数が大きく変動するのである。そして、検索を行うタイミングによって、「東京に行く」と「東京へ行く」のヒット数の多寡が逆転してしまうのである。このようなものは、言語研究のための満足行く証拠とは言えないだろう。
言語研究は科学的な研究である。科学において、何か主張するときの証拠は基本的には再現可能でなくてはならない。サーチエンジンのヒット数は、再現可能性が薄く、科学研究における証拠とするに足らないのである。
ヒット数は言語全体を代表していない
また、サーチエンジンのヒット数は、言語全体を代表しているわけではない。そもそも、ヒット数は、(インデクスされた)ウェブ上の文書のうち、特定のキーワードを含む文書の数を表していると考えられる。ヒット数を使って研究するということは、証拠としてウェブの言語しか見ていないということになりかねない。
自然言語は、ウェブ上にのみ出現するというわけではない。日常の会話や、印刷された文章など、言語の大きな部分は、ウェブ以外の場所に存在するのである。こういったものを無視して、ウェブ上の文書だけを着目するのはあまり良い態度だとは思えない。
「私はウェブ特有の文体を調べているのだ」と強弁することは可能である。ただ、Google がインデクスしているウェブページは、明らかにウェブ上の文章のすべてではないということ [5] に注意が必要である。
どう対処すれば良いか?
というわけで、私としては、Google などのサーチエンジンのヒット数を言語研究の証拠にすることはおすすめしない [6] 。
数値が欲しいのならば、しっかりと構築されたコーパスを使うと良い。ちゃんとしたコーパスなら、完全なものではないが、ジャンルごとのバランスを考えて構築されているので、ウェブ上の文書ばかりということにはならない。また、同じコーパスを使いさえすれば、別の人が別の時点で調査しても、結果は同じになる。つまり、再現可能なのだ。
- 可能形で、「ら」が抜けて見える現象のことをら抜き言葉と呼ぶ。「見る」の可能形を「見られる」でなく、「見れる」にする現象のことだ。 [↩]
- 佐藤亘・打田研二・山名早人 (2011).「検索エンジンのヒット数に対する信頼性評価 指標の提案とその妥当性検証」『情報処理学会研究報告〔情報学基礎研究会報告〕』8. [↩]
- 図中のローマ数字の I, II, III はそれぞれ、「数日にわたってコンスタントに変動が大きい期間」、「2, 3日といった短い期間の間に連続して急上昇と急降下が見られる期間」、「一度急上昇(降下)し, しばらく安定してから急降下(上昇)してもとの値に戻る,という期間」を示している(佐藤ら 2011)。 [↩]
- 田野村忠温 (2008). 「日本語研究の観点からのサーチエンジンの比較評価―Yahoo!とGoogleの比較を中心に―」 『計量国語学』 26 (5), 147-157. [↩]
- 例えば、『フューチャーインサイト』の「Facebookとの情報の非対称性はGoogleにとって即死につながるリスクである」という記事などを参考されたい。 [↩]
- もちろん、研究を始めるに当たって、見当をつけるぐらいなら別に良いと思う。それでも公刊する論文とかにはあまり載せたくない。 [↩]