Rのバージョン3.6.0がリリース
概要
統計処理言語の R のバージョン3.6.0が、2019年4月26日に公開された。この新リリースでは、離散一様分布に従う乱数の生成手法が変更されたり、文字列を表現式 (expression) に変換する新しい関数が導入されたりした。
バージョン3.6.0のリリース
2019年4月26日、R のバージョン3.6.0がリリースされた。コードネームは Planting of a Tree(木を植えること)である。バージョン3.6.0での変更点の詳細は、Rアナウンスメーリングリストでのバージョン3.6.0リリースの通知(R 3.3.0 is released、英語)を参照されたい。
ちなみに、Rのバージョンごとに付けられるコードネームは米国の漫画 Peanuts から取られるのが通例。今回の Planting of a Tree は、おそらく1963年3月3日付けの作品から取られたもの。この作品ではルーシーとライナスが木を植えるというもので、その中でルーシーが “The planting of a tree shows faith in the future” (強調引用者)と言っている。

バージョン3.6.0での主な変更点
バージョン3.6.0での変更点のうち、自分が気になった点をいくつか紹介したいと思う。
文字列処理
- 文字列の冒頭や末尾にある空白文字を取り除く
trimws()関数にwhitespaceオプションが加わった。このオプションで何を空白文字と見なすか指定できるようになった。- これまでのバージョンと同様に、
trimws()はデフォルトでは[ \t\r\n](半角スペース、水平タブ、キャリッジリターン、ニューライン)を空白文字と見なす。しかし、デフォルトの空白文字の範囲だと、全角スペースなどが空白文字と見なされないことになる。 - Unicode に収録されている空白文字全般を
trimws()での空白文字として指定するには、whitespace="[\\h\\v]"と指定すればよい。なお、PCRE形式の正規表現で "\h" は水平方向の空白文字、"\v" は垂直方向の空白文字を示す。 stringrパッケージにstr_trim()という関数がある。この関数も文字列の冒頭や末尾にある空白文字を取り除く関数であるが、こちらはデフォルトで全角スペースなども空白文字として取り除いてくれる。trimws()でわざわざオプションを指定するよりも、str_trim()を使った方が便利だろう。- 以下の例では、「あああ」の前後に全角スペースがある。
trimws()では特に指定しないかぎり、全角スペースは消えない。
- これまでのバージョンと同様に、
trimws(" あああ ")
# [1] " あああ "
trimws(" あああ ", whitespace="[\\h\\v]")
# [1] "あああ"
stringr::str_trim(" あああ ")
# [1] "あああ"
統計処理
summary()関数のデフォルトのメソッドで、分位数の計算方法をquantile.typeオプションで指定できるようになった。- 例えば、
xを数値ベクトルとするとき、summary(x)を実行すると、その四分位数が表示される。その四分位数の計算方法が指定できると言うことである。 - 分位数の計算方法については、
quantile()関数のマニュアルを参照のこと。
- 例えば、
- 分散を計算する関数
var()が、factor を引数に取れなくなった。標準偏差を計算する関数sd()でも同様。 - t検定を行う
t.test()関数が平均(の差)の標準誤差を返すようになった。この関数が返すリストのstderrという部分にこの標準誤差の値が入っている。
x <- 1:10 y <- 11:20 result <- t.test(x, y) result$stderr # 結果は [1] 1.354006
描画
- 軸ラベルを描画するときに、軸ラベル同士の間に空けるべき隙間の最小値を設定できるようになった。
- この値を設定するには、
axis()関数のgap.axisオプションで設定したい数値を指定するか、plot()する際にxgap.axisやygap.axisオプションで設定したい数値を指定する。
- この値を設定するには、
- 棒グラフを描く
barplot()関数が、モデル式 (formula) を書く形式に対応するようになった。例えば、barplot(GNP ~ Year, data = longley)で以下のような出力が得られる ((これまでのバージョンでは、barplot()の最初の引数(=棒の高さに対応する数値)として取れるのはベクトルか行列のみであった。そして、今回挙げた出力例はbarplot(longley$GNP, names.arg = longley$Year)のように書かざるをえなかった。)) 。
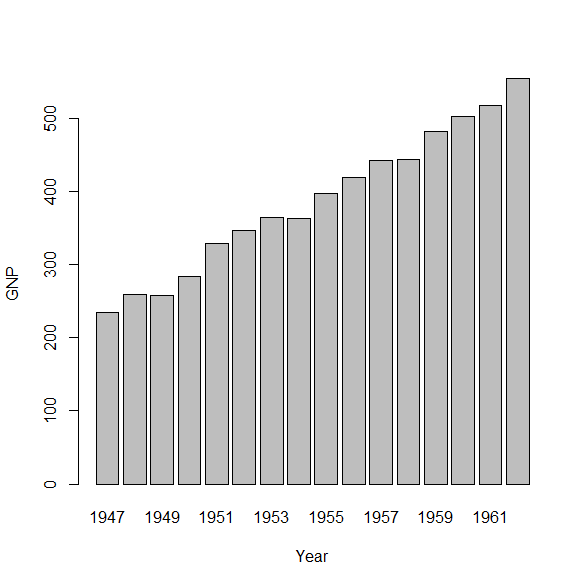
- カラーパレットを作るために使う関数(
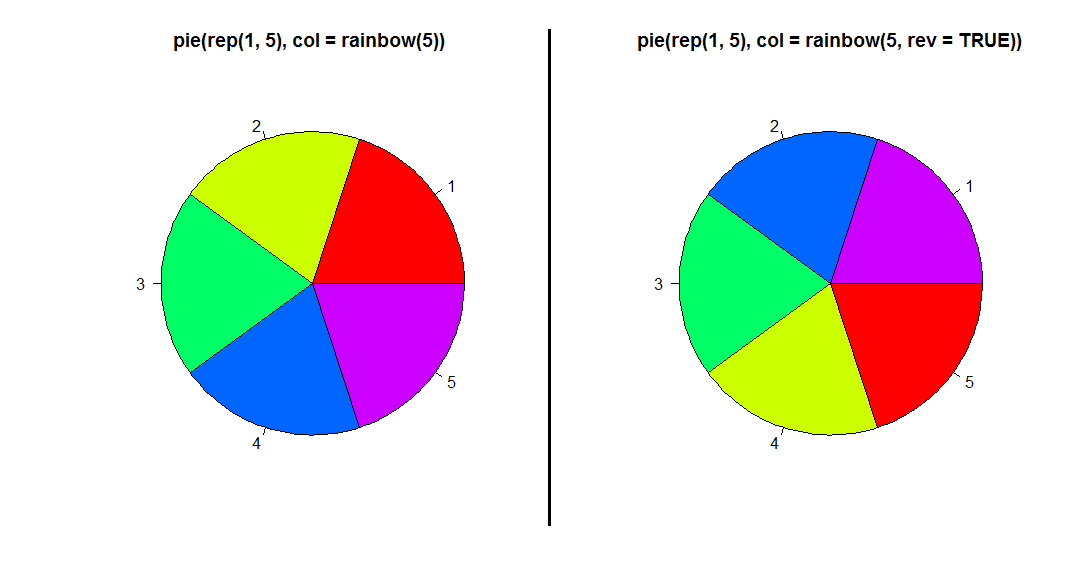
rainbow()やterrain.colors()など)に、色の順番を逆順にするためのオプションrevが加わった。rev = TRUEと指定すると、デフォルトとは色が逆順になる。- 事例として、
pie(rep(1, 5), col = rainbow(5))とした場合と、pie(rep(1, 5), col = rainbow(5, rev = TRUE))とした場合を掲げる。
- 事例として、
数値計算
gamma()関数やlgamma()関数が Inf を返すときなどに警告が発せられなくなった。- 旧来のバージョンでは、
gamma(1e10)を計算すると、 Inf が返り、さらに「 ‘gammafn’ 中の値が範囲を超えています」という警告メッセージが出た ((lgamma()関数の場合は、lgamma(0)のようにすると同様の警告メッセージが出ていた。)) 。 - バージョン3.6.0 以降ではこのような警告メッセージは出ない。
- 内部的に
gamma()関数を使っている他の関数でも警告メッセージは発せられなくなった。例えば、階乗を計算するfactorial()関数でも警告メッセージは出ないようになった。
- 旧来のバージョンでは、
- ローマ数字を使った演算ができるようになった。厳密に言うと、
romanクラスのオブジェクトに対して、算術演算・比較演算・論理演算が可能になった。
three <- as.roman(3) five <- as.roman(5) three + five # 結果は VIII three > five # 結果は FALSE sum(as.roman(1:10)) # 結果は LV (=55)
乱数生成
- 離散一様分布に従う乱数を生成する手法(
sample()などで使われている)が変わった。これまでのバージョンでは、大きな母集団においては、一様とはほど遠いものであったが、このバージョンから改善された。RNGkind()を実行すると、Rでどのような乱数生成手法が用いられているかを表示することができる(下のコード参照)。この実行結果の3番目に出てくるのが、離散一様分布に従う乱数を生成する方法であり、"Rounding" か "Rejection" のいずれかになる。前者は古い生成手法を使っていることを示し、後者は改善された新しい手法を使っていることを示す。RNGkind(sample.kind = "Rounding")を実行すると、バージョン3.6.0より前の古いやり方で離散一様分布に従う乱数を生成するようになる。古いバージョンで計算したときと同じ結果を再現する場合にのみ用いるべきである。RNGkind(sample.kind = "Rejection")を実行すると、バージョン3.6.0で改善された新しいやり方で離散一様分布に従う乱数を生成するようになる。特に理由がなければ、こちらを使うべきである。
RNGkind() # [1] "Mersenne-Twister" "Inversion" "Rejection"
プログラミング
- 新しい関数として、
str2langとstr2expressionが加わった。str2langは文字列を呼び出し (call) あるいはアトミックな定数などに変換する ((マニュアルを見ると、“a call or simpler”(呼び出しまたはそれより単純なもの)を返すと書いてある。)) 。str2expressionは文字列を表現式 (expression) に変換する。- これまでの R でも
parse()関数を使えばできたことだが、それが簡潔に表現できるようになった。
- これまでの R でも
- 新しい関数として、
asplit()が導入された。これは、配列(行列を含む)を分割してリストにするものである。
(x <- matrix(1 : 6, 2, 3)) # 以下の結果が返る # [,1] [,2] [,3] # [1,] 1 3 5 # [2,] 2 4 6 asplit(x, 1) # 行ごとに分割 # 以下の結果が返る # [[1]] # [1] 1 3 5 # # [[2]] # [1] 2 4 6 asplit(x, 2) # 列ごとに分割 # 以下の結果が返る # [[1]] # [1] 1 2 # # [[2]] # [1] 3 4 # # [[3]] # [1] 5 6