はじめに
データクリーニングは、データ分析の際に非常に重要なプロセスの1つであるが、データ分析の教科書では必ずしも十分に扱われていない。そこで、現実のデータクリーニングがどのように行われるかについて、一事例を紹介したいと思う。具体的には、統計処理に適したプログラミング言語のRを用いて、粗悪なデータから簡単な折れ線グラフが作成できる程度のきれいなデータにするまでのデータクリーニングを実施していく。
本記事の対象読者
本記事は、既存のデータに対して自らの手でデータ分析を実施している人、または実施しようと考えている人を主な対象にしている。データ分析の際にどのようなロジックでデータクリーニングをしていけば良いのかということについて考えるヒントとしていただければと思う。本記事では、R を用いてデータクリーニングを行うが、基本的な考え方は他のツールを使ったデータクリーニングにも共通するところがあるので、R を使わない人にとっても有用な内容が含まれていると思う。
また、自らの手でデータを扱わない人であっても、1) データクリーニングという行為が大変であることを知り、2) データクリーニングの負荷が少ないデータを提供することの必要性を認識するために、この記事は役立つと思う。
この記事は非常に長いものになっている。この長さは、データクリーニングの繁雑さに比例したものである。つまり、データクリーニングが容易ではなく、うんざりするほどのものであることを反映している。自らの手でデータを扱わない人は、この分量を見てデータクリーニングの大変さを感じていただければと思う。
この記事で扱う事例
この記事では、データクリーニングの事例として、日本の文部科学省の学校基本調査のデータから、日本の男のみの高校と女のみの高校の数の推移をグラフ化することを取り上げる。以下のようなグラフを作り上げるのがこの事例のゴールである。
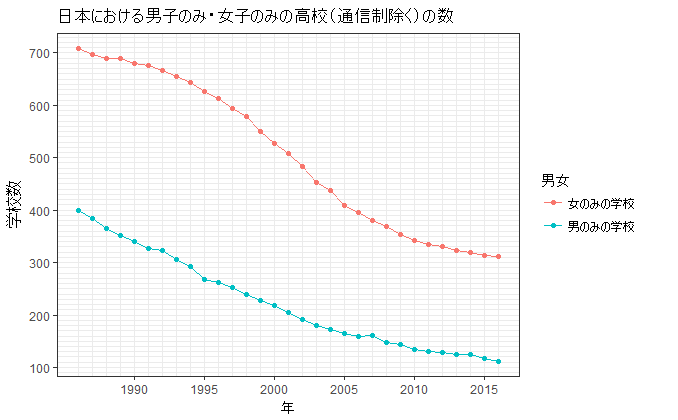
やることは、年度ごとに学校の数を調べて、それをまとめた折れ線グラフをつくるだけだ。高度な統計分析は何もない。正直言って、小学校の算数の授業で習う程度のことしかやっていない。だが、日本政府が提供している統計データの形式は、計算機上で扱いにくいものになっている。このため、扱いやすい形式に変換する作業が非常に面倒になる。
この記事では、この面倒な作業を以下の順序で説明していく。
- 手に入るデータの問題点
- データの入手方法
- (1個のファイルを対象とした)データクリーニングの方法
- すべての年のファイルに対して同じ処理を繰り返し行う仕組み
- 最終的なグラフの出力
この記事でのデータクリーニングに当たってのRのスクリプトは GitHub にアップロードしてある。
e-Stat で提供されているデータの問題点
文部科学省の学校基本調査に、日本の全日制・定時制高等学校について男女別学校数をまとめた統計表がある。この統計表は、日本の政府統計がまとまっている e-Stat から Excel ファイルの形式で手に入れることができる。
この統計表には、日本の全日制・定時制高等学校で、「男女ともにいる学校」、「男のみの学校」、「女のみの学校」、「生徒のいない学校」がそれぞれ何校あるかという情報が載っている。これを使えば、男のみの高校と女のみの高校の数の推移が分かることになる。
学校基本調査での「男のみの学校」は、女性の入学を許しているかどうかに関係なく、調査時点で男性しか在籍していない学校のことを指す。このため、そもそも男性しか入学できない学校のほか、男女とも入学できる「共学校」であるのに男性しか在籍していない学校も含まれている。
「女のみの学校」も同様で、男性の入学を許しているかどうかに関係なく、調査時点で女性しか在籍していない学校のことを指す。
しかしながら、e-Stat で提供されている Excel ファイルには以下のような問題点がある。
- 年度ごとにファイルが分かれている。
- ファイルごとにデータが収録されているフォーマットが少しずつ違う。
最初の問題点は、すべての年のファイルに対して繰り返し同じ処理を行う必要があることを意味する。1つずつ手作業で行うと失敗を招きやすいので、うまく繰り返しができるプログラムを書く必要がある。
ただし、2番目の問題点で挙げたように、ファイルごとにフォーマットが少しずつ違うので、フォーマットの差異を吸収できるようなデータクリーニング処理をしなくてはならないのである。
Excel ファイルを用いるのではなく、e-Stat のAPI機能 を用いればもっと扱いやすいデータが手に入るのではないかと考えた人もいるかもしれない。しかし、API 機能で取ることができたのは、平成20年度から22年度の3年度分のみであった。他の年度のものは API 機能で取ることができなかった。このため、Excel ファイルを用いざるをえなかった。
データの入手――必要な Excel ファイルのダウンロード
まずは、e-Stat から男女別学校数をまとめた統計表の Excel ファイルをダウンロードしよう。先に述べたように、1年度につき1ファイルなので、必要となる年度の Excel ファイルを1つずつ手動でダウンロードする。この作業もできれば自動化したいところであったが、自動化のスクリプトを書く方がよほど時間がかかりそうだったので、手動で処理することにした。
ダウンロードしたのは、1986年から2016年までの31年分である。今回の分析では、ワーキングフォルダの中に original-data という名前のフォルダを作り、その中に Excel ファイルをまとめた。
ダウンロードしたファイルを保存する際には、ファイル名を西暦4桁の年にした。すなわち、1986年の調査結果が入った Excel ファイルは 1986.xls という名前で保存し、2010年の調査結果が入った Excel ファイルは 2010.xls という名前で保存した。
ファイル名を西暦年としたことには理由がある。おそろしいことに、e-Stat から手に入る Excel ファイルには、それが何年の調査結果なのかを示す情報がまったく入っていない。このため、ファイル名に西暦年の情報を入れておくことで、あとでデータクリーニングをするときにファイル名から西暦年の情報が得られるようにしておくのだ。
データクリーニング
データに対する注釈的要素の除去
e-Stat からの Excelファイルには、データそのもののほかに、データに対する注釈的要素も含まれてしまっている。ここでの注釈的要素として、統計表のタイトルと脚注がある。具体例として、2015年のファイルを見てみよう。
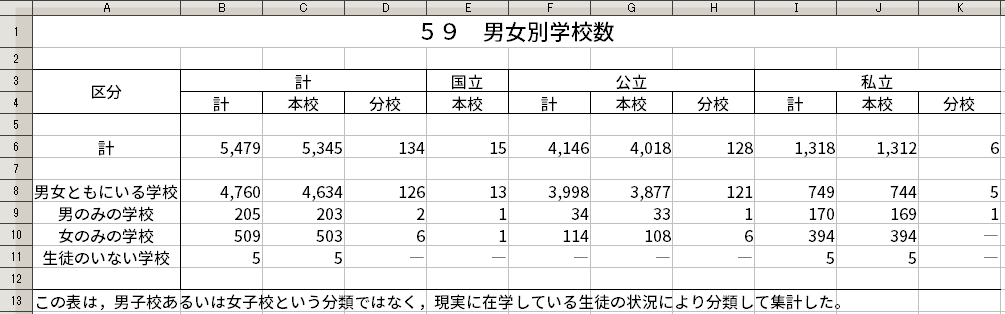
このファイルには、「97 男 女 別 学 校 数」というタイトル、「1 この表は,男子校(中略)集計した。」という脚注が存在している。こうした注釈的要素は、データを解釈するときの助けにはなるが、分析したいデータそのものではない。このため、注釈的要素を取り外す必要がある。
タイトルや脚注がどの年度のファイルでも同じ位置に記されていれば、これを除去するのは簡単であっただろう。しかし、残念なことに、年度ごとにタイトルや脚注の位置が少しずつ異なっている。どうやれば除去できるだろうか。
タイトルがある行に着目してみると、タイトルそのものが入っているセル以外は、すべて何も入っていない空セルになっている。これはどの年度についても同じである。
空セルはRに読みこまれると、NAとして扱われる。よって、タイトルがある行は、NAが並ぶ中で、1つだけ例外的に NAでないセル(=タイトルそのものが入っているセル)があるということになる。
脚注が入っている行も同様で、ほとんどのセルが NAで、例外的に NAでないセルがあるという状況になる。ただし、年度によって、NAでないセル(=脚注そのものが入っているセル)が1セルの場合もあれば、2セルの場合もある。
これに対して、データそのものが入っている行は、NA となるところがほとんどない。あったとしてもごくわずかである。
ここで、行内の NA の個数と、その行のセルの総数を比較してみよう。タイトルや脚注が入っている行では、行内の NA の個数と、その行のセルの総数(=列数)がほぼ等しい。これに対して、データそのものが入っている行は、行内の NA の個数がその行のセルの総数(=列数)に比べてかなり少なくなる。
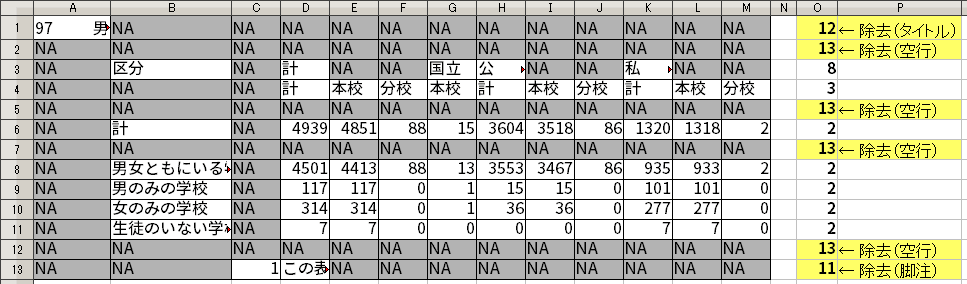
NA の個数と、その行のセルの総数の比較。よって、行内の NA の個数が、列数から2を引いたものより多くなるような行を取り外すことで、注釈的要素がある行を取り外すことができる [1] 。
R では、以下のように filter() 関数を使い、行内の NA の個数が、列数から2を引いたものより少なくなるような行のみを残すようにしている。
filter(rowSums(is.na(.)) < ncol(.)-2)
なお、この式により空行も除去される。空行では行内の NA の個数が列数と同じになるため、上記の filter() 関数の処理で消える。
空列の除去
e-Stat からの Excelファイルには、見栄えを良くしたかったのか、空行や空列が存在している。これらも分析には関係ないので、除去する必要がある。
空行や空列というのは、要するにまったくデータが入っていない行や列のことである。Rで読みこむと、NA だけが並んだ列や行になる。
よって、空行を除去したければ、行内の NA の個数がその行のセルの総数(=列数)と等しい行を除去すればよいし、空列を除去したければ、列内の NA の個数がその列のセルの総数(=行数)と等しい列を除去すればよい。
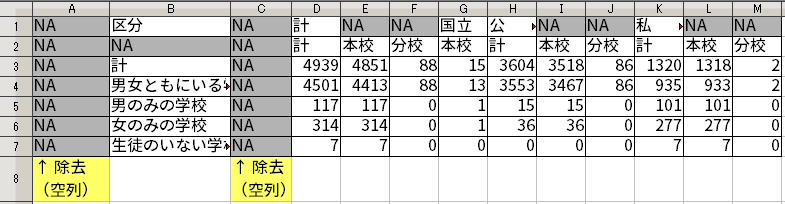
NA が並んだ状態になる。そして、実は先ほどデータに対する注釈的要素を除去した際に、空行も一緒に除去されている。このため、あとは空列だけ除去すればよい。Rでは次のように処理する。
select_if(colSums(is.na(.)) != nrow(.))
変数をすべて列にする
今までの処理によって、不要な部分をかなり削り取ることができた。例えば、2015年度のデータは、今までの処理で次のようなものになっている。
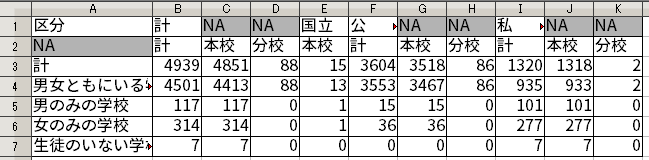
これはかなりすっきりしているのだが、変数がさまざまな構造で表現されているという問題がある。例えば、(1) 学校の設置者(国立か公立か私立か)を示す変数、および (2) 本校・分校の別を示す変数は行になっている。これに対し、(3) 性別による学校の分類を示す変数は列になっている。行と列とで統一が取れていないのである。
この節でいう「変数」は、プログラミングのときの変数と言うよりは、統計学で説明変数や目的変数というときの変数である。
データクリーニングにおいて、「整然データ」(tidy data) という考え方がある。整然データでは、変数がすべて列をなすようになっており、データ処理がしやすくなっている。
もっと詳しく知りたい人は、「整然データとは何か」という記事も参照のこと。
今回のデータクリーニングでも、整然データに変換していきたいと思う。今のところ、行で示されている変数が2つ(学校の設置者、本校・分校の別)、列で示されている変数が1つ(性別による学校の分類)、行と列にまたがって示されている変数が1つ(学校数)ある。これらの変数をすべて列で示すようにしたい。
これを整然データにするための大まかな方針を述べておこう。まず行と列を入れ替える。これで、列で示されている変数を2つ、行で示されている変数を1つにする。そして、行で示されている変数をうまく集めて変換することで、すべての変数を列で示すようにする。これには、tidyr パッケージの gather() 関数を用いる。ただし、実際のデータクリーニングに当たっては、他にも細々とした調整をしていく必要がある。
以下で、もう少し詳しく見てみよう。
変数に見出しをつける
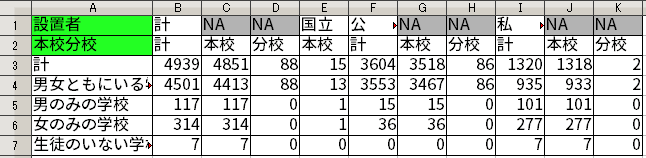
1行目は学校の設置者(国立か公立か私立か)を示す変数で、2行目は本校・分校の別を示す変数になっている。しかし、1行目の冒頭には「区分」とあるだけで、何が何だか分かりにくいし、2行目については NA からはじまっており、これまた何が何だか分かりにくい。
変数に見出しをつける意味で、各行の最初のセルに見出しとなる文字列を入れよう。R では inset() 関数でセルの内容を書き換えることができる。
inset(1, 1, "設置者") %>% inset(2, 1, "本校分校") %>%
転置による行と列の入れ替え
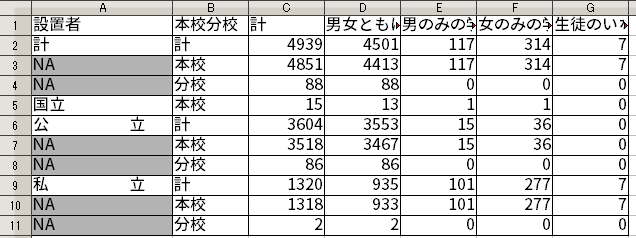
さらに、先に述べたように、行と列を入れ替える。つまり、転置を行えばよい。Rで転置をするには、t() 関数を使う。これでもともと列で示されていた「設置者」・「本校分校」の2つの変数が行で表されるようになった。
ただし、Rの仕様により、データフレームを t() 関数で転置すると、データフレームではなくなり、ただの行列(matrix クラス)になってしまう。ただの行列だと扱いにくいので、as_data_frame() 関数でデータフレームにしておく。
列名の設定
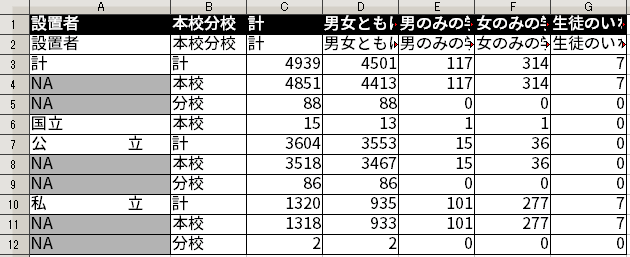
このようにしてできたデータフレームには、列名が設定されていない。列名に相当する内容は、このデータフレームの1行目に書かれている。よって、まず1行目を列名として指定する。列名を設定した後は、1行目は要らなくなるので、これを削除する。
列名を指定するには、set_colnames() 関数を使う。
1行目を削除するには、1行目以外の行を抽出すればよい。行の抽出には slice() が使える。引数として、-1 を指定することで、「1行目以外」を示すことができる。
文字列内の余計な空白の除去
e-Stat で提供されているデータでは、印刷したときの表の見た目を良くするためか、「公 立」のように設置者を示すところに余計な空白が入ってしまっているものがある。単に「公立」とすれば良いのに、「公」と「立」の間に何個も空白を入れて幅を広げて見せているのだ。
ややこしいことに、年度によって入っている空白の数が違う。また、こうした空白が入っていない年度のデータもある。
こうした違いを乗り越えて空白を除去するには、単純に正規表現を使って空白が消えるように置換すれば良い。R での文字列操作は、stringr パッケージを使うのが便利だ。ここでは、文字列置換のために、このパッケージの str_replace_all() 関数を使う。
mutate(設置者 = str_replace_all(設置者, "\\s+", ""))
なお、ここでは mutate()という関数を用いて、列の中身を修正している。この関数は dplyr パッケージに含まれるもので、データフレームの列に対して修正などを行う際にしばしば用いられる。
セルの結合がもたらした問題の処理
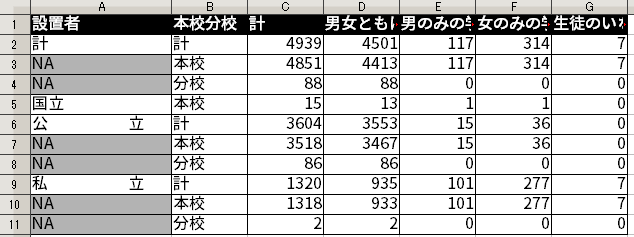
さて、設置者を示す列で、NA となっている部分が残っている。これはもともとの Excel ファイルでセルの結合を使っていた名残である。
結合されたセルの意味
どういうことか説明するために、最小限の例を持ち出してみたいと思う。
もともとの Excel ファイルでは見た目のために、以下のように複数のセルを1つに結合して1個の値を入れていた。このように結合はされているものの、人間の眼からすると「公立の計が3,604」、「公立の本校が3,518」、「公立の分校が86」という意味が表されていることは容易に理解できる。

こうした結合されたセルが R に読みこまれるとどうなるのだろうか。以下に示すように、結合が解除され、1番左上のセルだけに値が残り、その他のセルは NA が入れられてしまう。

NA が発生してしまっている。ただ、ここの NA には1番左上のセルと同じものが入ることが期待される。先ほど触れたように、「公立の計が3,604」、「公立の本校が3,518」、「公立の分校が86」という情報を示す必要があるのだから、ここの NA には「公立」が入ることが期待される。
結局の所、結合が解除されて生まれた NA のすべてに、結合されていたときに入っていた値を穴埋めすれば良いことになる。
結合の後始末
今までデータクリーニングを進めてきたものに戻ろう。設置者を示す列でNA と入っている部分を、そのセルの上にある内容で穴埋めしていけばよい。
こういうときのために便利な関数が、tidyr パッケージに入っている fill() である。平たく言えば、これは NA がある場合にその上の(NA 以外の)セルの内容をコピーしてくれる関数である。
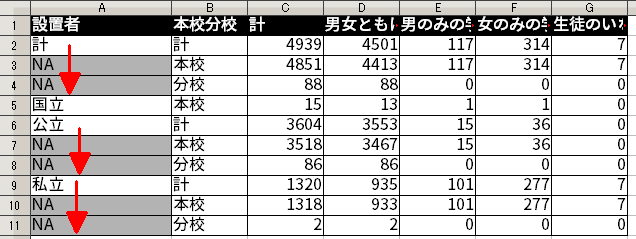
fill() 関数が行うことのイメージ。この関数を使うことで、結合の後始末として以下のように穴埋めすることができた。
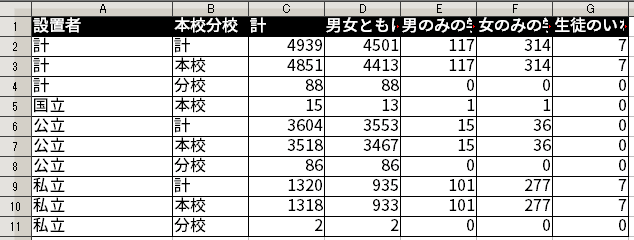
fill() 関数で穴埋めした結果。残った変数を列で表現する
今まで長々と処理をしてきたが、性別による学校の分類が行で表現されており、まだ1列で表現されていない。また、学校数も1列で表現されていない。
tidyr パッケージに入っている gather() を使えば行で表されている変数が列で表されるように変換できる。以下では、「設置者」・「本校分校」はそのままにして、残りを処理している。
gather(key = 男女, value = 学校数,
-one_of("設置者", "本校分校"))
その結果の一部を示すと以下のようになる。
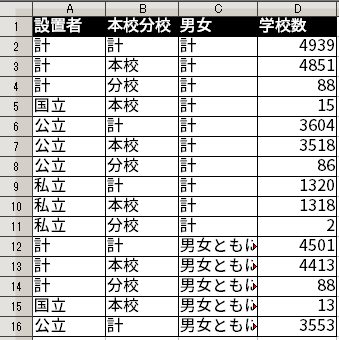
これで、「設置者」・「本校分校」・「男女」・「学校数」という変数がすべて1列で表されることになった。そして、これは整然データになっている。
合計を示すデータの削除
e-Stat から手に入れた Excel ファイルには、合計を示すデータが含まれている。例えば、公立の男のみの学校で、本校であるものと分校であるもののの合計を示したデータが入っていたりする。あるいは、男女の区分や国公私立などの区分に関係なく、すべての高校の数を足しあわせた合計を示したデータも入っている。
こうした合計を示すデータは有用ではあるが、データクリーニングの際には削除した方が良い。合計を示すデータを消すことで、データの構造が簡素になり、扱いやすくなる。
消さない場合、「設置者」の列に「計」が残ったままになる。「設置者」が「国立」だったり、「公立」だったりするのは問題ない。しかし、「設置者」が「計」だというのは何が何だか良く分からない。合計は他のデータと違うレベルのデータであるのに、それが他のものと混在してしまうと扱いにくくなるのだ。
また、合計を示すデータを削除したとしても、あとから必要なときに他のデータから簡単に算出することができる。だから、削除してしまっても全く問題はない。
合計を示すデータを削除するには、行の中で「計」が含まれるものを削除すればよい。そして、これは行の中で「計」が含まれないものだけを選択することと同じことである。よって、条件に当てはまるものだけを選択するために、以下のように filter_all() 関数を使えば良い。
filter_all(all_vars(!str_detect(., "計")))

学校数ゼロを示すデータの処理
男女別学校数の統計表の Excel ファイルでは、該当する学校が存在しないことを示すために、横棒が表示されることがある。これは、要するにそのカテゴリに当てはまる学校の数がゼロだということだ。というわけで、こうした横棒はゼロに置換しておけば良い。
置換をするには、先ほど触れたように stringr パッケージの str_replace_all() 関数を使えば良い。ここでは、「―」と「-」を「0」に置換する。
mutate(学校数 = str_replace_all(学校数, "[―-]", "0"))
なお、e-Stat から手に入る Excel ファイルでは、この横棒が「―」である場合と、「-」である場合がある [2] 。まったく同じ横棒に見えるかもしれないが、実は符号位置が異なっている。最初の「―」はホリゾンタル・バーと呼ばれるもので、Unicodeでの符号位置は U+2015になる。2番目の「-」は全角のハイフンマイナスと呼ばれるもので、Unicodeでの符号位置は U+FF0Dになる。
いずれにせよ、これら2種類の横棒を「0」に置換すること自体は容易である。むしろ、横棒が2種類あるということに気づくことに時間がかかってしまうことが大変である。
さて、実は「学校数」の列は文字列 (character) として扱われている。読みこんだときに、数字だけでなくて、横棒も入っていたために文字列と見なされてしまったのだ。このままでは数値としての計算ができないので、これを整数 (integer) に変換する必要がある。
mutate(学校数 = as.integer(学校数))
年を示すデータの追加
先に触れたように、もともとの Excel ファイルには何年のデータなのかという情報がないため、今まで作成してきたデータフレームの中にもまだ年を示すデータが入っていない状況である。
このため、年を示す列を付け加える必要がある。新たな列を加えるときにも mutate() 関数が使える。
year というオブジェクトの中に西暦年が入っているとすれば、以下のようにして、年を示す列を付け加えることができる。
mutate(年 = year)

長々と説明してきたが、これでファイル1個分のデータクリーニングが終わった。とは言え、まだ1個分、すなわち1年分のデータしか処理していないのだ。
すべての年のファイルに同じ処理を行う
学校数の変遷を見るためには、対象となる時期のファイルすべてに対してデータクリーニングを行わなくてはならない。
1つずつデータクリーニングをするのは大変なことのように思われるかもしれないが、繰り返し同じ処理を行うのはコンピュータが得意とするところである。
ここでは以下のような方針で、複数のファイルに対するデータクリーニングを行う。
- Excelファイルのファイル名が入ったベクトル
fnamesを作成する。 - 与えられた1個のファイル名に対し、そのファイル名に対応する Excel ファイルを読みこんで、データクリーニングを実施して、きれいになったデータフレームを返すような関数
extract_school_num()を作成する。 fnamesにファイル名が入っている Excel ファイル1つ1つについて、extract_school_num()でデータクリーニングを行い、その結果をデータフレームとしてschool_numの中にまとめる。
ファイル名が入ったベクトルの作成
今回の分析では、Excel ファイルをワーキングフォルダの中の original-data というフォルダにまとめて入れた。つまり、"./original-data/"というパスにあるExcel ファイルのファイル名をすべて取ってくれば良い。
具体的には、以下のようにする。
xls_path <- "./original-data/" fnames <- dir(pattern = "\\.xlsx?$", path = xls_path)
dir() という関数で、patternという引数で指定した形のファイル名になっていて、pathという引数に指定したパスの中にあるようなファイル名のリストが得られる。なお、"\\.xlsx?$"というのは、ファイル名の末尾が .xls か .xlsx であることを示している。今回手に入れたデータは、Excel ファイルと一口に言っても、.xls と .xlsx の両方があるので、このような書き方をする必要がある。
Excel ファイルを読みこんでデータクリーニングを行う関数の作成
次に、Excel ファイルを読みこんでデータクリーニングを行う関数として、extract_school_num() というものを作成する。これは、ファイル名を示す文字列 fname [3] を引数にとるように設定してある [4] 。
extract_school_num() はおおよそ以下のようなものになっている。データクリーニングを実施する後半部分は、先に説明したことの繰り返しになるので省略した。
extract_school_num <- function(fname){
year <- as.integer(str_sub(fname, 1, 4))
# Excelファイルの読み込み
data <- read_excel(paste0(xls_path, fname),
col_names = FALSE)
# データクリーニングの実行
# (中略)
return(data)
}
上記の year <- as.integer(str_sub(fname, 1, 4)) という部分はファイル名から西暦年を取得するためのものである。Excel ファイルの中身には年の記述がないため、西暦年をファイル名にしておいたのであった。例えば、2015年のものならば、“2015.xlsx” というファイル名にしていた。こうしたファイル名の冒頭4文字を拾うことで、西暦年を得ることができる。具体的には、stringr パッケージの str_sub()関数で、fname の冒頭4文字を拾い上げた上で、これを as.integer() で整数に変換し、結果を year というオブジェクトに格納している。そのままだと文字列なので、整数に変換する必要があるのだ。先ほどデータクリーニングの説明の最後で、年を示すデータの追加をしていたが、それはここで作られた year からデータを得ている。
次に来るのが、Excel ファイルの読み込みを行う部分である。R で Excel ファイルを読みこむためのパッケージにはさまざまなものがあるが、ここでは readxl パッケージを用いる。このパッケージの read_excel() 関数を使えば、.xls 形式も .xlsx 形式も読みこむことができる。
その後、先に説明したようなデータクリーニングを実施し、最後の return() 関数で1年分のデータを返すことになる。
1つ1つのファイルの処理結果をまとめる
ここまで準備ができれば、purrr パッケージの map_df() 関数を使って、1つ1つのファイルを処理した結果をデータフレームにまとめることができる。
school_num <- map_df(fnames, extract_school_num)
ここで、map_df() 関数は、最初の引数としてとった fnames の要素1つ1つ(≒ Excel ファイル1つ1つ)に対して extract_school_num() 関数を適用し、その結果を1つのデータフレーム school_num にまとめあげる。
これで、すべての Excel ファイルからのデータが1つのデータフレームにまとまったことになる。1986年から2016年までの31個の Excel ファイルに分かれていたものが、この school_num という単一のデータフレームに収められたのだ。これは整然データになっており、ここから容易にさまざまな可視化や分析を実施することができる。
グラフの出力
ここまで来れば、グラフを出力するのは容易である。
以下のコードに示すように、データフレーム school_num に対し、簡単な下準備を行い、ggplot()を使ってグラフを描く。
school_num %>%
# 下準備
group_by(男女, 年) %>%
summarise(学校数 = sum(学校数)) %>%
ungroup() %>%
filter(男女 == "女のみの学校" | 男女 == "男のみの学校") %>%
# ggplot でグラフを描く
ggplot(aes(x = 年, y = 学校数, colour = 男女)) +
geom_line() + geom_point() +
scale_x_continuous(breaks = seq(1990, 2015, by=5), minor_breaks = 1986:2016) +
scale_y_continuous(breaks = seq(0, 900, by=100),
minor_breaks = seq(0, 900, by=10)) +
theme_bw() +
ggtitle("日本における男子のみ・女子のみの高校(通信制除く)の数") +
ylab("学校数")
上記のコードの前半部分は、年ごとに「女のみの学校」、「男のみの学校」それぞれの学校数を出すための下準備である。元々のデータフレームでは、設置者別・本校分校別に学校数が分かれてしまっているので、これらを合算している。
折れ線グラフの出力は、ggplot(), geom_line(), geom_point() まであればできるが、軸やタイトルなどをきれいに表示するために、色々な設定を後から加えている。
冒頭に掲げたように、ここまでの処理で以下のようなグラフが出力できる。
おわりに
今回はデータクリーニングに R を用いたが、他の統計処理ソフトやプログラミング言語を用いたとしてもデータクリーニングが困難であることには変わりはない。なぜかと言えば、提供されている元データが乱雑で不統一である点は変わらないからである。どのようなツールを使うにせよ、このような粗悪さに対処するには、相当の手間と時間がかかるのである。
現実には今回扱うデータよりもさらに粗悪なデータがある。ゴミとクズとカスを足して3で割ったようなデータは世の中にあふれているのである。それらに対するデータクリーニングはさらにややこしいことになる。
たかがデータクリーニング、されどデータクリーニング。簡単そうに見えて、なかなか難しいのである。
ところで、このような手間を防ぐにはどうすれば良いのだろうか。思うに、データを作成・提供する時点で扱いやすい形にしておくのが重要であると思う。
データを提供する側が乱雑な形で出すのであれば、利用する側が個別にデータクリーニングの手間をかけなくてはならない。しかし、データを提供する側が一度計算機で扱いやすい形にしておけば、データを利用する側は特にすることがなくなる。つまり、最初に扱いやすい形にしておけば、全体としては労力が減るのである。
その意味でも、データクリーニングの負荷が少ないデータを提供することは必要なのである。
- ここで2を引くのは、脚注が入っている行において
NAでないセルが最大で2つあるためである。 [↩] - 本文中で触れた横棒が入っている事例は、セル内に「―」などの横棒が入っているため、Rで読みこむとそのまま横棒が入ってしまう。実を言うと、このほかに、セル内に「0」という値が入っているものの、Excel の表示形式の機能を使って横棒が表示されるようになっている Excel ファイルもある。こうしたものをRで読みこむときは、表示形式が無視されるので、「0」が読みこまれる。「0」が読みこまれる分には特に困ることはない。 [↩]
- 先に作成したファイル名が入ったベクトルは
fnamesで複数形を示す -s をつけてある。extract_school_num()の引数はfnameであり -s が付いていない。 [↩] - 本来であれば、引数がしっかりとファイル名を示す文字列になっているかどうかを判定する機能を設けておいた方が良いのだろうが、ここではそこまでしていない。 [↩]