Rのバージョン3.2.0がリリース
概要
統計処理言語の R のバージョン3.2.0が、2015年4月16日に公開された。この新リリースでの主な変更点について解説する。
バージョン3.2.0のリリース
2015年4月16日、R のバージョン3.2.0がリリースされた。コードネームは Full of Ingredients(素材でいっぱい)である。バージョン3.1.0がリリースされたのは、2014年4月10日なので、およそ1年を経てマイナーバージョンアップが行われたことになる ((なお、バージョン3.1.0と3.2.0との間に3回のリビジョンが行われている。すなわち、2014年7月10日にバージョン3.1.1が、10月31日にバージョン3.1.2が、2015年3月9日にバージョン3.1.3がそれぞれリリースされている。)) 。(2016年5月6日:この段落の誤字修正)

バージョン3.2.0での変更点の詳細は、Rアナウンスメーリングリストでのバージョン3.2.0リリースの通知(R 3.2.0 is released、英語)を参照されたい。
バージョン3.2.0での主な変更点
以下で、バージョン3.2.0での変更点のうち、重要だと思われる点をいくつか紹介しよう。
入力関係
- 固定長フォーマットのデータを読み込むための函数 read.fwf で、fileEncoding オプションが指定できるようになった。これによって、読み込むデータのエンコーディングを指定できるようになった。データ交換形式のデータを読み込むための函数 read.DIF でも同様に fileEncoding オプションが指定できるようになった。表形式のデータを読み込むための函数 read.table には前から fileEncoding オプションでエンコーディングを指定できた。今回のバージョンアップによって、read.table と同様に read.fwf や read.DIF でも読み込むデータのエンコーディングが指定できるようになったのである。
- 指定したパスが存在するかを調べる函数として、dir.exists が新しく導入された。
- 指定したオブジェクトが存在するかを調べ、もし存在するのであればそのオブジェクトを取得する函数として get0 が新しく導入された。今までは、存在するかを調べる函数 exist とオブジェクトを取得するための函数 get を組み合わせる必要があったのだが、今回のアップデートにより、get0 という1つの函数で表現できるようになった。
描画
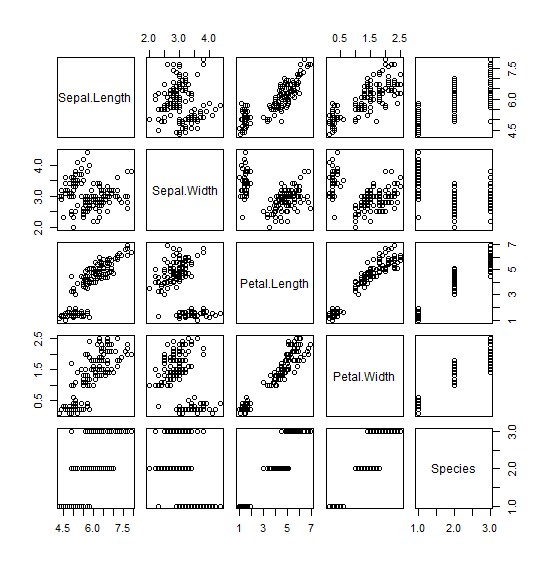
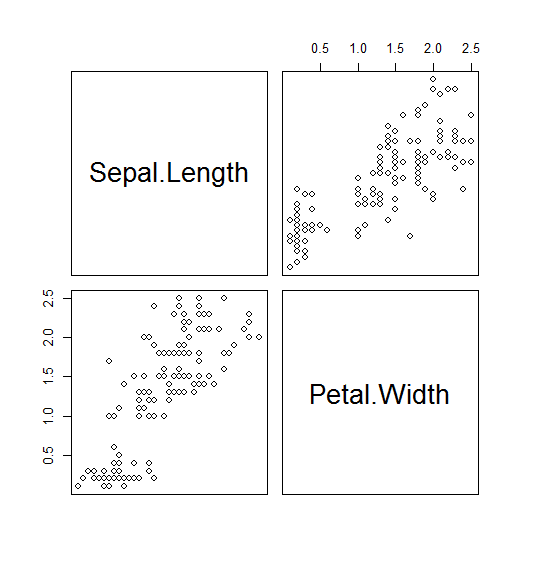
- 散布図行列を描く pairs 函数に horInd オプションと verInd オプションが加わった。それぞれ、生成される散布図行列のどの行を描くか、どの列を描くかを指定することができる。
pairs(iris) pairs(iris, horInd=c(1,4), verInd=c(1,4))
- ラスタ (raster) オブジェクトが plot 函数で描画できるようになった。以下のスクリプト例では、まず「黒→白→灰」というラスタを r に入れ、描画する。次に、「赤 (#FF0000) → 緑 (#00FF00)」というラスタを r2 に入れ、描画する。
r <- as.raster(c(0, 1, 0.5)) plot(r) r2 <- as.raster(array(c(1, 0, 0, 1, 0, 0), c(2, 1, 3))) plot(r2)

文字列処理
- 文字列の冒頭と末尾の空白を消す ((スペースだけでなく、タブ、改行コードも消される。)) ための函数 trimws が新しく導入された。データの整形の時に役立つだろう。デフォルトでは冒頭と末尾の空白の双方を消す。冒頭だけ、あるいは末尾だけ消したければ、which オプションで指定すれば良い。詳しくは以下の例を参考のこと。
str <- " foo bar " # 結果は "foo bar" trimws(str) # 冒頭の空白だけ消す。結果は "foo bar " trimws(str, which="left") # 末尾の空白だけ消す。結果は " foo bar" trimws(str, which="right")
- tools ライブラリに toTitleCase 函数が新しく導入された。これは、タイトルを表示するときのために、文字列に含まれる単語を大文字始まりにする函数だ。ただし、a や for といった機能語は大文字始まりにしない。以下の例では、”a New Item for Students” という結果が返される。
library(tools)
toTitleCase("a new item for students")
リスト
- リストの要素になっているベクトルの長さを返す函数として lengths が新しく導入された ((length とは違う函数なので注意する必要がある。length は要素の数を返す。)) 。以下の例では、x.list というリストの要素として、長さ4のベクトル、長さ2のベクトル、長さ3のベクトルがある。ここで、lengths(x.list) とすると、4 2 3 が返る ((ここで length(x.list) とすると、3 が返る。x.list には3つの要素が含まれているからである。)) 。
x1 <- c(1, 3, 5, 7)
x2 <- c("a", "b")
x3 <- c(F, F, T)
x.list <- list(x1, x2, x3)
lengths(x.list)
- NA(欠損値)の有無を判定する函数 anyNA に recursive オプションが加わった。このオプションが真 (T) である場合は、リストの中身に NA があるかどうかも調べるようになる。下記の例では、y.list というリストの直接の要素としては NA が存在しない。だから、anyNA(y.list) を実行すると、FALSE が返る。しかし、y.list の最初の要素の中には NA が含まれているので、anyNA(y.list, recursive=T) を実行すると TRUE が返る。
y1 <- c(0.5, NA, 3)
y2 <- c("foo", "bar")
y3 <- c(T, F, T)
y.list <- list(y1, y2, y3)
anyNA(y.list)
anyNA(y.list, recursive=T)