はじめに
Unicode は世界の様々な文字をコンピュータ上で統一的に扱うための国際規格である [1] 。Unicode には毎年のように新しい文字が追加されており、2020年3月にリリースされた Unicode 13.0 では 5,930字が追加されている [2] 。
Unicode 13.0 での漢字の追加
Unicode 13.0 で追加された文字の大半は漢字である。Unicode 13.0 では、漢字 [3] を追加するためにCJK統合漢字拡張G (CJK Unified Ideographs Extension G) というブロックが設けられた。このブロックに新規の漢字として追加されたのは4,939字である。さらにこれ以外のブロックにもいくつか新規の漢字が追加された。
ただし、Unicode 13.0 で追加された漢字のほとんどは、日本語とは関係がない。簡体字のほか、中国語の方言で使われている漢字であるとか、甲骨文字を現在通行の字体に改めたものや、明の皇族の名前に使われている漢字といったものが多い。日本語ではとうてい使用する場面は無さそうなものばかりだ。
しかし、追加された漢字の中に、日本語で使われると言ってもよい漢字が2つある。すなわち、
- 「日本で最も画数が多い字」とも呼ばれる「雲」3つと「龍」3つを合わせた「たいと」
- 宮沢賢治の詩で使われている「鏡」を4つ組み合わせた字
である。これら2つの文字について以下で簡単に紹介したいと思う。
たいと

「たいと」は画像に挙げたように、「雲」3つと「龍」3つで構成された漢字である。なお、この字は「だいと」や「おとど」と読むという説もある。画数はなんと84画である。姓に使われる漢字であると言われるが、その根拠はあやしい。漢字学者の笹原宏之は、「たいと」がいわゆる幽霊文字ではないかと述べている [5] 。要するに、もともと存在しない字だったものが何らかの理由で実在する文字と誤認されてしまったというわけだ。
「たいと」は、Unicode では U+3106C というコードポイントが与えられている。「たいと」を Unicode に入れる提案は UTCDoc L2/15-260 “Request to add 1,656 U-source ideographs” という文書に載っている。この文書では「たいと」の出典として『難読姓氏辞典』 [6] と『直感力が身につく「漢字・熟語」クイズ』 [7] が挙げられている。しかし、後者は前者を典拠としているので、実質的には出典は『難読姓氏辞典』 のみである。
「たいと」については、以下のページに色々と情報があるので、もっと詳しく知りたい方はそちらを参照されたい。
- レファレンス協同データベースの「総画84画のこの漢字(「雲」3つと「龍」3つを上下に合した字)は漢字辞典でどのように扱われているか。」という質問への回答
- Wikipedia日本語版の「「たいと」の項
- 『たいと・おとど』考
宮沢賢治の「鏡」×4

宮沢賢治の「岩手軽便鉄道の一月」という詩に「鏡」を4つ組み合わせた字が出てくる。この詩は、国立国会図書館デジタルコレクション所収の『農民とともに』で読むことができる。
この「鏡」を4つ組み合わせた漢字は、Unicode では U+30F54 というコードポイントが与えられている。「たいと」と同様に、この字を Unicode に入れる提案は UTCDoc L2/15-260 “Request to add 1,656 U-source ideographs” という文書に載っている。
補:Unicode 13.0 における部首の例示フォント変更
Unicode では、以下の2つのブロックに部首を表す文字が含まれている。
- 「康煕部首」 (Kangxi Radicals):『康煕字典』に載っている214種類の部首を収録。
- 「CJK部首補助」 (CJK Radicals Supplement):『康煕字典』にはない形の部首を収録。例えば、日本の新字体での「⻯」や中国の簡体字での「⻈」(ごんべん)などが含まれる。
Unicode 13.0 では、これらのブロックの部首の例示のために用いられるフォントが変更された。この変更は、 UTCDoc L2/19-212 “Proposal to change the font for the CJK Radicals Supplement & Kangxi Radicals blocks” という文書で提案されたものである。
なぜ変更の提案がなされたのだろうか。
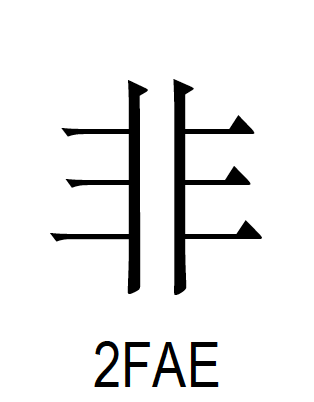

まず、「康煕部首」については、Unicode 12.1 までの例示用の字形で、『康煕字典』と微妙に異なる形になっているところがあった。これを『康煕字典』に合った形にするために、Unicode 13.0 で変更されたというわけだ。
例えば、「⾮」(あらず)という部首は、Unicode 12.1 までの例示では左側が水平線3本と縦線1本で構成されていた。しかし、『康煕字典』での「⾮」の左側は、水平線2本に右上がりの横線、そして縦線の最後がはらう形になっている。Unicode 13.0 では、『康煕字典』に合った形に変更された。ちなみに、部首の「⾮」(あらず)は、Unicodeでは KANGXI RADICAL WRONG という名称になっている。WRONGは英語で「間違っている」という意味にもなるので、まさに〈間違っている〉康煕部首が間違っていたのだ [11] 。


また、「CJK部首補助」については、Unicode 12.1 までその部首が用いられている国でふつうに使われている形で例示されていないところがあった。Unicode 13.0 ではこれが実態に合った形に変更された。
例を挙げておこう。主に日本で使われる部首「⻯」(りゅう)は、Unicode 12.1 までの例示では最初の画が点になっていた。しかし、日本の明朝体では「⻯」の最初の画は短い横棒となるのがふつうである。この日本の実態に合わせて、Unicode 13.0 での例示でも最初の画が短い横棒になった。
- Unicode Inc. (n.d.). What is Unicode?. 2020年4月13日閲覧 Unicode Inc. About the Unicode® Standard. 2020年4月13日閲覧 [↩]
- Unicode Inc. (2020, March 20). Announcing The Unicode® Standard, Version 13.0. http://blog.unicode.org/2020/03/announcing-unicode-standard-version-130.html [↩]
- 厳密に言うと、字喃 なども含まれている。 [↩]
- Glyphwiki の画像を使用。 [↩]
- 笹原宏之.(2011). 「幽霊文字からキョンシー文字へ?」https://dictionary.sanseido-publ.co.jp/column/kanji_genzai082 [↩]
- 大野史朗・藤田豊〔編〕.(1977). 『難読姓氏辞典』東京:東京堂出版. [↩]
- 馬場雄二.(2011). 『直感力が身につく「漢字・熟語」クイズ』東京:PHP研究所. [↩]
- Glyphwiki の画像を使用。 [↩]
- The Unicode Standard, Version 12.1: Archived Code Chartsより引用。 [↩]
- The Unicode Standard, Version 13.0: Archived Code Chartsより引用。 [↩]
- 〈間違っている〉康煕部首が間違っていたというネタは私の独創ではなく、UTCDoc L2/19-212 に書いてある話である。 [↩]
- The Unicode Standard, Version 12.1: Archived Code Chartsより引用。 [↩]
- The Unicode Standard, Version 13.0: Archived Code Chartsより引用。 [↩]